Miscellaneous Study Notes
Note: pieces of knowledge (to be organized) from online (or other) readings, thoughts, etc.
-
The Spearman correlation is just the Pearson correlation using the ranks (order statistics) instead of the actual numeric values. The answer to your question is that they're not measuring the same thing. Pearson: linear trend, Spearman: monotonic trend. That the Pearson correlation is higher just means the linear correlation is larger than the rank correlation. This is probably due to influential observations in the tails of the distribution that have large influence relative to their ranked values. Tests of association using the Pearson correlation are of higher power when the linearity holds in the data.
-
$
- it's equivalent to dot product in Euclidean space.
- $
$X\otimes X$: outer product, is doing ALL POSSIBLE multiplications of one set of numbers or functions with another.
- it is also called as tensor product,
- it's equivalent to a matrix multiplication and the result of an outer product is a matrix.
$X\times Y$: cross product; $X \times Y = ||X||\ ||Y||\sin\theta\ \mathbf{n}$
-
$\theta$ is the angle between $X$ and $Y$; $\mathbf{n}$ is the unit vector perpendicular to the plan containing $X$ and $Y$, in the direction given by the right-hand rule.
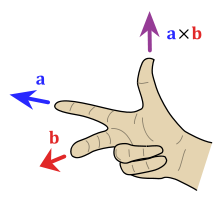
-
-
Norm: $||X|| = \sqrt{X\cdot X} = \sqrt{
- $L_p$: $||X||_p = \left(\sum_{i=1}^n |x_i|^p\right)^{1/p}, 1\le p\le \infty$
- $L_1$: $||X||_1 = \sum_{i=1}^n|x_i|$
- $L_2$ or Euclidean norm: $||X||_2 = (\sum_{i=1}^n|x_i|^2)^{1/2} = \sqrt{X^TX}$.
- It is the most commonly encountered vector norm (often simply called "the norm" of a vector, or sometimes the magnitude of a vector)
-
Distance: the distance between two points $\mathbf{x, y} \in V$ in a vector space is defined as the norm of the difference $\mathbf{x-y}$
$$ d_p(\mathbf{x, y}) = ||\mathbf{x-y}||_p = \left(\sum_{i=1}^n|x_i-y_i|^p\right)^{1/p}, 1\le p\le \infty $$- $p=1$, city block or Mahattan distance: $d_1(\mathbf{x,y})=||\mathbf{x-y}||_1 = \sum_{i=1}^n|x_i-y_i|$
- $p=1$, Euclidean distance: $d_2(\mathbf{x,y})=||\mathbf{x-y}||_2 = \sqrt{\sum_{i=1}^n|x_i-y_i|^2}$
- $p=\infty$, Chebyshev distance: $d_{\infty}(\mathbf{x, y}) = ||\mathbf{x -y}||_{\infty} = \max_i|x_i - y_i|$
The three unit circles or spheres, are formed by all points $\mathbf{x}$ of unity norm $||\mathbf{x}||_p = 1$ with unity distance to the origin (blue, black, and red for $d_{\infty}$, $d_2$, and $d_1$, respectively).
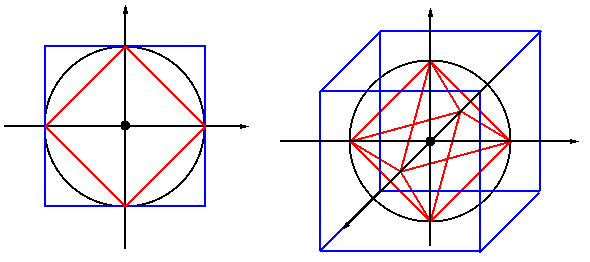
-
-
Inference for $\theta$ or inference for $E(\theta)$
- When the goal is to estimate $\theta$, then all you really need is to estimate $\theta$ to more accuracy than its standard error (in Bayesian terms, its posterior standard deviation). For example, if a parameter is estimated at $3.5 \pm 1.2$, that’s fine. There’s no point in knowing that the posterior mean is 3.538. To put it another way, as we draw more simulations, we can estimate that "3.538" more precisely–our standard error on $E(\theta|y)$ will approach zero–but that 1.2 ain’t going down much. The standard error on $\theta$ (that is, $sd(\theta|y)$) is what it is.
- This is a general issue in simulation (not just using Markov chains), and we discuss it on page 277 of Bayesian Data Analysis (second edition): if the goal is inference about $\theta$, and you have 100 or more independent simulation draws, then the Monte Carlo error adds almost nothing to the uncertainty coming from the actual posterior variance.
- On the other hand, if your goal is to estimate $E(\theta|y)$ to some precision, then you might want lots and lots of simulation draws. This would be the example where you actually want to know that it’s 3.538, rather than simply 3.5. In my applications, I want inference about $\theta$ and have no particular desire to pinpoint the mean (or other summary) of the distribution; however, in other settings such as simulating models in physics, these expectations can be of interest in their own right.
- For Bayesian inference, I don’t think it’s generally necessary or appropriate to report Monte Carlo standard errors of posterior means and quantiles, but it is helpful to know that the chains have mixed and to have a sense that further simulation will not change inferences appreciably. Diagnostics are far from perfect, and so it’s good that people are doing research on these things.
-
Normalizing constant in Bayesian posterior distribution (Why can we ignore the normalizing constant in the posterior distribution?)
According to your notation, Bayes's formula is actually
$$Pr(\theta∣\text{data})=Pr(\text{data}∣\theta)Pr(\theta)/Pr(\text{data})$$The denominator, $Pr(data)$, is obtained by integrating out the parameters from the join probability, $Pr(data,\theta)$. This is the marginal probability of the data and, of course, it does not depend on the parameters since these have been integrated out.
Now, since:
$Pr(data)$ does not depend on the parameters for which one wants to make inference;$Pr(data)$ is generally difficult to calculate in a closed-form; one often uses the following adaptation of Baye's formula:
$$Pr(\theta∣\text{data})\propto Pr(\text{data}∣\theta)Pr(\theta)$$Basically, $Pr(data)$ is nothing but a normalising constant, i.e., a constant that makes the posterior density integrate to one.
-
The subject which deals with maximizing or minimizing integrals of functions is the calculus of variations and one of its basic tricks is to write the integrand as a function of $x$, the function, and its derivatives. This sets us up to use a general theorem to the effect that any function $\hat{m}$ that minimizes L must also solve Euler-Lagrange equation.
-
In survival analysis the Cox model is preferred to a logistic model, since the latter one ignores survival times and censoring information.
-
The basic conclusion of the article is that thinning of chains is not usually appropriate when the goal is precision of estimates from an MCMC sample. (Thinning can be useful for other reasons, such as memory or time constraints in post-chain processing, but those are very different motivations than precision of estimation of the posterior distribution.)
-
Why it doesn't make sense in general to form confidence intervals by inverting hypothesis tests
The standard analysis that Imbens proposes includes (1) a Fisher-type permutation test of the sharp null hypothesis–what Imbens referred to as"testing"–along with a (2) Neyman-type point estimate of the sample average treatment effect and confidence interval–what Imbens referred to as "estimation."
Imbens claimed that testing and estimation are separate enterprises with separate goals and that the two should not be confused. I [Cyrus] took it as a warning against proposals that use "inverted" tests in order to produce point estimates and confidence intervals. There is no reason that such confidence intervals will have accurate coverage except under rather dire assumptions, meaning that they are not "confidence intervals" in the way that we usually think of them.
The idea is that you’re fitting a family of distributions indexed by some parameter $\theta$, and your test is a function $T(\theta,y)$ of parameter $\theta$ and data $y$ such that, if the model is true, $Pr(T(\theta,y)=\text{reject}|\theta) = 0.05$ for all $\theta$. The probability here comes from the distribution $p(y|\theta)$ in the model.
In addition, the test can be used to reject the entire family of distributions, given data $y$: if $T(\theta,y)=\text{reject}$ for all $\theta$, then we can say that the test rejects the model.
This is all classical frequentist statistics.
Now, to get back to the graph above, the confidence interval given data $y$ is defined as the set of values $\theta$ for which $T(y,\theta)!=\text{reject}$. As noted above, when you can reject the model, the confidence interval is empty. That’s ok since the model doesn’t fit the data anyway. The bad news is that when you’re close to being able to reject the model, the confidence interval is very small, hence implying precise inferences in the very situation where you’d really rather have less confidence!

Sometimes you can get a reasonable confidence interval by inverting a hypothesis test. For example, the $z-$ or $t-$test or, more generally, inference for a location parameter. But if your hypothesis test can ever reject the model entirely, then you’re in the situation shown above. Once you hit rejection, you suddenly go from a very tiny precise confidence interval to no interval at all. To put it another way, as your fit gets gradually worse, the inference from your confidence interval becomes more and more precise and then suddenly, discontinuously has no precision at all. (With an empty interval, you’d say that the model rejects and thus you can say nothing based on the model. You wouldn’t just say your interval is, say, [3.184, 3.184] so that your parameter is known exactly.
-
Methods to compare $q$th percentile (e.g. median) of a variable between two groups: point estimate & confidence interval
Note: this is different from estimating median of difference using Hodges-Lehmann method
-
Bootstrap
-
Quantile regression
-
Binomial based probability model (this is for one sample estimate)
-
Every percentile $p$ of a random variable $X$ dichotomizes that variable into a binary random variable, say $Y = \mathcal{I}(X\le p)$, where $Pr (Y = 1) = p$. That is, in a sample of size $n$, the total number of observations with $X\le \text{it’s }p$th percentile $\sim \text{Binomial}(n, p)$
-
To construct the $(1-\alpha)\%$ confidence interval for the $p$th percentile of variable $X$ based on a sample with size of $n$:
-
Find the lower and upper limits of number of cases, $l$ and $u$, which are symmetrical or almost symmetrical about $n*p$, such that $\sum_{k=0}^{u-1} Binom(n, k, p) - \sum_{k=0}^{l-1} Binom(n, k, p) \ge 1 - \alpha$
This is call the coverage probability.
# let p be the pth quantile l <- qbinom(alpha/2, n, prob = p, lower.tail = TRUE) u <- n - l + 1 -
The percentile confidence interval is then calculated as $[l/n, u/n]$
-
In the data, sort variable $X$ and find values correspond to its $l/n$th and $u/n$th percentiles. The resulting values are the $(1-\alpha)\%$ CI for the $p$th percentile of $X$
-
-
Note:
- The above CI is conservative as the coverage probability is $\ge 1-\alpha$
- The above CI is called the exact CI, in some cases it is not symmetrical about the point estimate
- See Meeker et. al. (2017) for an approximate method that give a symmetrical CI around the point estimate
-
-
CMH test vs McNemar’s test vs conditional logistic regression
Check Highlights on Hypothesis.io
-
CMH is a generalization of McNemar’s test when each pair is treated as a stratum
-
The null hypothesis for CMH test is the discordant probability is 0.5 (?check)
-
-
Understanding interaction term in regression
-
Adding interaction term in the model is to examine if the main effect of interest varies by another (pre-treatment) factor
-
If the interaction is significant, it means there is no overall "unique" treatment effect and the magnitude of the (overall) main treatment effect is not estimable
- The effect is estimable in a stratified analysis
-
In general, for a linear regression model, the estimate obtained by including the interaction, and then averaging over the data, reduces to the estimate with no interaction. (Gelman)
- Modeling interactions is important when we care about differences in the treatment effect for different groups, and post-stratification then arises naturally if a population average estimate is of interest.
-
How is regression adjustment differs from stratified analysis? Is regression model with interaction term equivalent to subgroup analysis?
- ⭐ Adjusted analysis with interaction term is usually preferred over subgroup analysis in general
- The real advantage of interaction effects is that it is more flexible when you have multiple explanatory variables. By estimating seperate regressions you force an interaction between the covariate you are interested in and all other explanatory variables, while with interaction effects you can choose which effect can change over and which remains constant. This is often very desirable as interaction effects tend to eat large amounts of statistical power.
- On a more mechanical level, with interaction effects (if you used the factor variable notation) you have all the power of margins, contrast, and marginsplot at your disposal.
-
A good illustrative example about how to understand the regression coefficients with interaction terms
- including only interaction term without main effect is basically grouping the samples into the categories defined by the unique combinations from the interaction and the estimate is the "average" of the samples within that category
- When one or both of the main effects are included in the model, the main effect(s) "takes away" part of the effect associated with it.
- The main effect included in the model would have all "average" values at its levels (i.e. no reference level created)
- The interpretation of the coefficient should then be adjusted appropriately based on the actual value of the corresponding main effects combination (the coefficients in the interaction terms are the difference between one level vs the reference level for that variable not included in the main effect conditional on the variable(s) included as main effect(s))
-
With the interaction term, the interpretation of one main effect is always dependent on the value of the other main effect, i.e. it’s conditional (on the other main effect) comparison or subgroup comparison
-
-
Types of regression sum of squares in regression analysis
-
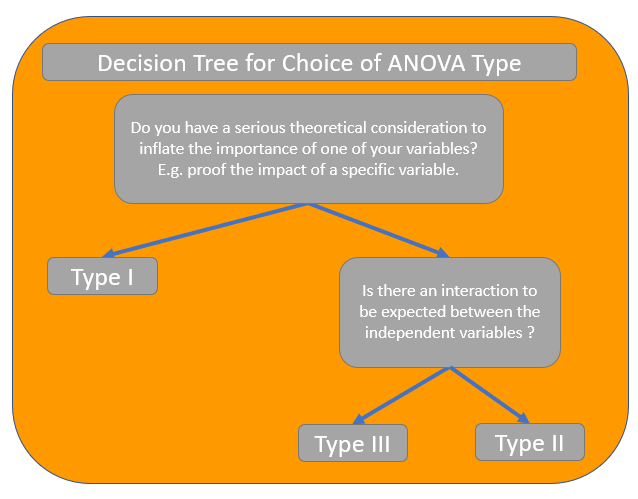
Type I: sequential. the order when a variable is added into a model matters, i.e. the SS is dependent on the order when the variable is added to the model.
-
Type II: hierarchical or partially sequential. Accout for other indpendent variables when calculating SS for one specific covariate; won't take an interaction effect
-
Type III: marginal or orthogonal. Accout for other indpendent variables when calculating SS for one specific covariate; will take an interaction effect when calculating SS for a covariate
-
Type IV: Goodnight or balanced.??
-
Total SS = Regression SS + Error (residual) SS
-
Total SS = sum of squares of differences between observed $Y$ and the overall average $\bar{Y}$;
-
Regression SS = SS of differences between predicted $\hat{Y}$ to the overall average $\bar{Y}$;
-
Error sum of SS = SS of differences between observed $Y$ and predicted $\hat{Y}$
-
-
When there is no interaction, Type II == Type III. Type I is seldomly used.
-
-
Hodges-Lehmann estimator (of location shift)
- It is the median of the "differences"
- It is NOT the difference b/t two medians
-
Homoscedasticity (in linear regression diagnosis) means that the conditional variance of the error term is constant and does not vary as a function of the explanatory variable. To check this assumption, we can
- plotting residuals vs. individual x variables
- plotting residuals vs. fitted outcome variable (y fitted values is a function of all explanatory variables)
-
If two statistics have non-overlapping confidence intervals, they are necessarily significantly different but if they have overlapping confidence intervals, it is not necessarily true that they are not significantly different.

-
Derive confidence interval from p-value or vice versa (under the normality assumption)
-
Knowing p-value and the point estimate, we can derive the corresponding confidence interval when normal approximation is valid:
- P-value $\rightarrow$ $Z$ score under $N(0, 1)$
- with $Z$ score, point estimate, and the null hypothesis of the parameter of interest, we can derive the standard error (SE) of the point estimate, since
- Then two-sided $(1-\alpha)*100$% CI is $\bar{x} \pm Z_{1-\alpha/2}*SE(\bar{x})$
-
From CI to p-value:
- from CI we can get the $SE(\bar{x})$, with which we then can construct the $Z$ score as in the formula above
- With $Z$ score, we can then calculated one- or two-sided p-value based on standard normal distribution
- Note: one- or two-sided p-value ($p$) can be used to get the one- or two-sided $(1-p)*100%$% CI just as how we use the significance level $\alpha$: $|\hat{x} - \theta_0|$ is the half width of the two-sided $(1-p)*100%$% CI or the width of the one-sided $(1-p)*100%$% CI.
-